最优化
在《R语言——数值分析》一文中,我提到将迭代法求解方程或方程组求解作为机器学习算法讲解的开端,但是对于很多机器学习初学者而言,为什么会以最优化问题作为机器学习的开篇呢?机器学习和最优化之间的联系又是什么呢?由于对机器学习领域不太了解,大多初学者会简单的认为机器学习只不过是模型的选择或是参数的迭代等。他们会基于《模式分类》一书中的“天下没有免费的午餐”定理固执的认为,对于不同领域或者不同类型的数据,必须要通过实验才能发现哪种学习算法或模型更适合现有数据源,所以就会盲目地相信某些人口中发文章既是换模型、调参数。多么天真的想法啊!等等,跑题了。。。
咳咳,回到正题上,随着大数据的到来,并行计算的流行,实际上机器学习领域的很多研究者会把重点放在最优化方法的研究上,如large scale computation。那么为什么要研究最优化呢?我们先从机器学习研究的目的说起。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法,这些算法可以从数据中自动分析获得规律,并利用规律对未知数据进行预测,并可用于发现数据之间隐藏的关系,解释某些现象的发生。至于为什么要让机器去做这些事情,原因很简单,数据量和维度过于庞大,无法通过人脑简单的处理或分析这些数据。比如,我们无法通过百万级的DNA序列分析各序列和疾病发生的关系,也无法在一定有限的时间内标定出1万张图像上人脸的位置。所以 研究者倾向于建立一些机器学习模型,通过输入一个样本(一个人的DNA序列或者是一副图片),输出样本的标签(是否患病、头像的位置)。这些学习模型里有大量可以调整的参数,它们通过调整参数组合,拟合高维空间训练样本数据的分布,识别出数据和标签之间复杂的关系。目前已有的神经网络、支持向量机、AdaBoost、卷积神经网络等算法,它们的共同特点是通过调整参数让模型的目标函数尽可能大或者小(如logistic回归是使得分类错误率尽量小)。为了达到该目的,不同的机器学习算法首先会设定不同的目标函数,然后给参数赋上随机初值,最后用各种下降法更快更好地寻找能让分类错误率更小的参数组合。
所以,从广义上讲,机器学习算法的本质上是优化问题求解,例如,梯度下降、牛顿法、共轭梯度法都是常见的机器学习算法优化方法。那么有人肯定会有疑问,这不还是调参数、选择参数么?这个参数优化与之前的调参的概念是不同的,之前说的调参是针对算法中的自由参数(即通过经验指定的参数,用过weka或者R的人应该知道,如SVM中的gamma或者logistic回归中的惩罚因子lamda),这些参数主要是控制学习模型的泛化能力,防止过拟合。而这里通过优化算法迭代出的参数则是目标函数中待求解的参数,例如,神经网络中各隐含层节点的权值、logistic回归中各自变量的系数。对于不同目标函数和不同优化算法,产生的问题也各不相同,比如某些目标函数不是凸函数也不是无约束的优化问题,无法直接利用梯度下降算法求解,又例如梯度下降法往往只能保证找到目标函数的局部最小值,找不到全局最小值,那么该怎么解决这些问题呢?答案是不一味的强行采用梯度下降,而是引入其他变量(拉格朗日乘子)将有约束问题转化为无约束问题,也可以适当爬爬山,说不定能跳出小水沟(局部极小值)找到真正的深井(全局极小值),这种算法叫模拟退火。也可以增大搜索范围,让一群蚂蚁(蚁群算法)或者鸟儿(粒子群算法)一齐搜索,或者让参数巧妙地随机改变(遗传算法)。所以,如何更快的找到目标函数的全局最小值或者全局最大值,如何避免陷入局部最优解是优化算法研究的重点。
讲了这么多,主要是为了说明机器学习与最优化问题的联系,也为大家更好的理解后续机器学习算法提供基础。接下来,我们会把讲解重点放在放在最优化及凸优化理论上。
1. 最优化问题
数值优化问题或者简称为优化问题主要是求问题的解,优化问题具有以下一般形式:
\[minimize\ f_0(x)\quad subject\ to\ f_i(x)<b_i,\ i = 1,\ldots, m \quad (1.1)\]其中,函数\(f_0\)为目标函数,函数\(f_i:\mathbb{R}^n \rightarrow \mathbb{R}\)为不等式,或约束函数。\(x=(x_1, \ldots, x_n)\)为向量,是目标函数的待优化参数(optimization variables),也称为优化问题的可行解,常量\(b_1,\ldots, b_m\)称为边界或约束。当存在向量\(x^*\),使得满足上式约束的任意向量\(z\),存在\(f_0(x^*)<f_0(z)\),则向量\(x^*\)称为上式(1.1)的最优解。当不存在约束时,优化问题称为无约束的优化问题,反之,称为有约束的优化问题。对于有约束的优化问题,当目标函数以及约束函数\(f_i(x),\ i=0,\ldots,m\)满为线性函数,则称该优化问题为线性规划(linear programming)。例如,\(f_i(x)\)满足\(f_i(\alpha x + \beta y)=\alpha f_i(x) + \beta f_i(y)\);如果目标函数或者约束函数不满足线性关系,则称优化问题为非线性规划(nonlinear programming)。如果目标函数和约束函数都满足凸函数不等式的性质,即:\(f_i(\alpha x + \beta y) \leqq \alpha f_i(x) + \beta f_i(y)\),其中\(\alpha+\beta=1, \ \alpha\geqq 0,\beta\geqq 0\)则该优化问题可称为凸优化问题。很明显, 线性规划问题也服从凸优化问题的条件,只有\(\alpha\)和\(\beta\)具有一定的特殊取值时,不等式才能变成等式成立,因此,凸优化问题是线性规划问题的一般形式。
对于机器学习而言,其一般表现为从一系列潜在的模型集合中寻找一个模型能最好的满足先验知识以及拟合观测数据。模型训练的目的在于找到分类错误或者预测误差最小的模型参数值。相对于优化问题,这里所说的先验知识可以对应成优化问题的约束函数,而目标函数则是一个评价观测值和估计值差别的函数(均方误差函数),或者是评价观测数据服从某模型下某组参数值的可能性的函数(似然函数)。因此,还是像之前所说过的,机器学习其实就是一个优化问题,优化问题的相关研究进展会极大影响机器学习领域的发展。
最优化算法即用于求解优化问题的方法,啊,简直是废话。。。最优化算法的计算效率(时间复杂度和空间复杂度)会严重限制算法的应用,例如,对于非光滑函数,传统的优化算法一般不会有较好的效果;优化参数维度较高时,有些优化算法也不适用。优化问题中,最常见的是最小二乘问题和线性规划,接下来会对这两个基本的优化问题做简要介绍。
a. 最小二乘问题
最小二乘问题(Least-Square problems)是无约束优化问题,同时,目标函数是具有\(a_i^T x - b_i\)形式的线性表达式的平方和,其一般形式可记为:
\[minimize\ f_0(x)=\parallel Ax-b \parallel^2=\sum_{i=1}^{k}(a_i^T x - b_i)^2 \quad (1.2)\]其中,\(A\ni \mathbb{R}^{k\times n}, \ k\geqq n\)为观测样本集合,向量\(x\)为待优化参数。
最小二乘问题是回归分析的根本,最小二乘问题很容易辨认,当目标函数为二次函数时,即可认为该优化问题为最小二乘问题。我们学过的解决该问题的最简单的方法是最小二乘法,我们可以将式(1.2)简化为求解线性等式,\((A_T A)x=A_Tb\)。因此,我们可以获得求解该问题的解析式\(x=(A_T A)^{-1}A_T b\)。该方法的时间复杂度为\(n^2k\),当样本数量以及特征维度较低时(百维、千维),一般计算机会在几秒内求的最优解,当使用更好的计算资源时,对于同样的样本量计算时间会呈指数衰减(摩尔定律)。但是,对于需要满足实时计算要求时,如果样本特征维度高于百万级别,采用最小二乘法求解就会变的不可行。所以,我们一般会采用梯度下降等迭代优化方法求解上述目标函数的可行解,当然为了防止过拟合,可选择惩罚(regularization)或者偏最小二乘(weighted least-squares)解决该问题。
b. 线性规划
线性规划是优化问题的另一个重要分支,其一般形式为:
\[miniminze\ c_T x\quad subject\ to\ a_i^T x \leqq b_i,\ i=1,\ldots,m \quad (1.3)\]对于线性规划问题,不存在类似最小二乘问题的一步求解方法,即最小二乘法,但是可用于解决线性规划问题的方法很多,如simplex方法,内插点法。虽然无法直接一步求解,但是我们可以通过控制迭代次数或设置停止迭代条件来减少运算的时间复杂度,例如,内插点法的时间复杂度为\(n^2 m\),其中\(m \geqq n\)。另外,采用迭代法求解优化问题不一定能像最小二乘法一样求得全局最优解,但目前的迭代算法大多场合下可以达到最小二乘法一样的准确度,而且,可满足实时计算的需求。
同时,很多优化问题都可以转换成线性规划问题,如Chebyshev approximation problem:
\[minimize\ max_{i=1,\ldots,k}\mid a_i^T x - b_i \mid \quad (1.4)\]其中,x为待优化参数。Chebyshev优化问题与最小二乘问题类似,但最小二乘问题可微(矩阵半正定),而Chebyshev目标函数不可微,所以无法采用最小二乘法求解。我们需要将目标函数进行转化,即可转化成线性规划:
\[minimize\ t\quad subject\ to\ a_i^T x - t \leqq b_i,\ - a_i^T x - t \leqq -b_i,\ where i=1,\ldots,k \quad (1.5)\]这样,我们就可采用simplex等方法求解该对偶线性规划问题。
c. 凸优化
凸函数的定义在上面已经介绍过了,即:
\[minimize\ f_0(x)\quad subject\ to\ f_i(x)<b_i,\ i = 1,\ldots, m \quad (1.6)\]其中,函数\(f_0,\ldots,f_m: \mathbb{R}^n \rightarrow \mathbb{R}\)为凸函数。
凸函数定义为:
\(f_i(tx + (1-t)y) \leqq tf_i(x) + (1-t)f_i(y)\),其中\(t \geqq 0 \quad (1.7)\)
也就是说,凸函数其函数图像上方的点集是凸集,函数图像上的任意两点确定的弦在其图像上方,这里需要点明的是国内某些教材上关于凸函数和凹函数的定义与这里写的正好相反,这里的凸函数是直观视觉上的凹函数,即碗形函数。凸函数的定义在定义域C上的凸函数可表现为
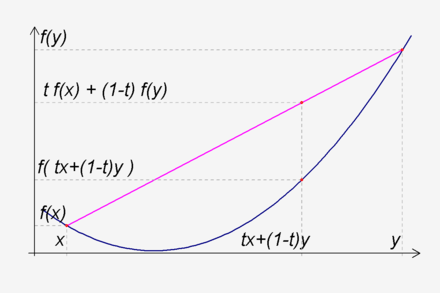
凸函数的判定方法一般是求解其二阶导数(如果存在),如果其二阶导数在区间上非负,则该函数为凸函数。当且仅当,二阶导数在区间上恒大于0,则函数称为严格凸函数。凸函数具有如下性质:
(1) 凸函数的一阶导数在区间内单调不减;
(2) 凸函数具有仿射不变性,即\(f(x)\)是凸函数,则\(g(y)=f(Ax+b)\)也是凸函数;
(3) 凸函数的任何 极小值都是最小值,严格凸函数最多有一个最小值;
(4) 凸函数在区间内(凸集内部)是正定的。最小二乘问题和线性规划问题都属于凸优化问题。
因为凸函数具有局部最优解就是全局最优解的优良性质,我们可以在求解过程不用过多考虑局部最优解和全局最优解的问题,因此,现有优化问题研究更多放在将一般形式的目标函数转化为凸函数后求解。而对于凸优化问题,我们可以采用熟知的内插法、梯度下降法、牛顿拉斐逊算法以及BFGS算法等。这些算法以及如何将优化目标函数转换为凸函数是本系列博客的主要阐述的问题。