1. 自步学习
在上一篇博文中,我们对自步学习的基本概念以及其优化方法做了简要概述,自步学习的核心在于如何定义样本的“难易程度”,例如:对于已知模型,损失小或似然值高的样本可视为“简单”样本。但是传统的自步学习仅考虑了样本的难易程度,没有考虑到样本的多样性(diversity),这里所谓的多样性是指自步学习选择样本的差异性,多样性倾向于选择样本间相似度低、差异性大的样本集合。一般而言,样本数据是非均匀采样或者不连续的(异质数据),因此我们可以假设样本数据是服从多个数据分布的样本集合,在利用自步学习选择样本时我们自然不希望仅从服从某一数据分布形式的样本集合(同质数据)中选择样本,而需要尽可能的从各个数据分布中都选择到一定数量的样本,保证数据的多样性,同时防止自步学习选择同质样本带来的欠拟合问题。这里还用高考模拟题来举例,假设我们物理和化学两个学科中,化学掌握的最好,物理最差。当第一次做理科综合的高考模拟题时,如果化学试题答对的居多,物理所有题目都没有完全答对。在不考虑学科的多样性时,因为化学试题多被认为是简单样本,物理试题则认为是复杂样本,自步学习的过程可能会倾向于去追求学习化学而舍弃物理,在经过多次学习后,会导致化学试题完全答对,而物理都回答错误,造成学生的偏科。
综上所述,我们更希望学生自己在自学过程中,掌握所有学科知识,考上理想的大学。在机器学习的概念中,我们也是希望自步学习选择过程中可以考虑到样本的多样性,保证模型不会欠拟合。CMU博士生Lu Jiang(现Google Research Scientist)提出的self-paced Learning with Diversity (SPLD)的核心思想就是解决自步学习样本选择多样性的问题。下图为Lu Jiang在2014年NIPS上发表的论文中SPLD的示意图,传统SPL倾向于只选择简单样本,但有可能来源于同一子类型(例如类别a),而SPLD则会从多个子类型(类别a、b和c)中选择出样本。本博文的重点就在于介绍该文章SPLD的优化过程(个人认为该优化方式很是巧妙,非常值得研究自步学习的同学们学习)。

2. SPLD模型
SPLD中对多样性的定义为选择的样本不相似或者不来源于同一聚类簇,假设样本的相关性与聚类簇有关,隶属于同一聚类簇的样本间(samples within a group)的相似性要高于聚类簇间样本的相似性(samples between groups)。因此,样本间的多样性可以表现为:物体识别中相同视频的帧认为属于同一簇,不同视频的帧之间具有多样性;样本空间的聚类簇间具有多样性等。
假设训练集\(X=(x_1, \ldots, x_n) \in \mathbb{R}^{m \times n}\)可以被划分或聚类至\(b\)个簇中:\(\mathbf{X^{(1)}}, \ldots, \mathbf{X^{(b)}}\),其中\(X^{(j)} \in \mathbb{R}^{m \times n_j}\)表示为属于第\(j\)个簇的样本集合,\(n_j\)表示第\(j\)个簇的样本数量,且\(sum_{j=1}^b n_j = n\)。因此,自步学习的参数向量\(v\)在SPLD中改为矩阵\(\mathbf{V}=[\mathbf{v^{(1)}}, \ldots, \mathbf{v^{(b)}}]\),其中\(v^{(j)} = (v_1^{(j)}, \ldots, v_{n_j}^{(j)}) \in [0, 1]^{n_j}\)。SPLD的关键是一方面可以与传统SPL类似,将非零权值赋给“简单”样本;另一方面,SPLD倾向于将所有非零元素分散至更多的簇,即分布到尽可能多的矩阵\(V\)的列向量\(v^{(j)}\)中,以保证样本的多样性。
SPLD的目标函数定义为:
\[(\mathbf{w}_{t+1}, \mathbf{V}_{t+1}) = argmin(r(\mathbf{w}) + \sum_{i=1}^n v_i f(\mathbf{x_i}, y_i, \mathbf{w}) - \lambda \sum_{i=1}^n v_i - \gamma ||\mathbf{V}||_{2,1}), \, \\ s.t. \, v \in [0,1]^n,\]其中,\(\lambda, \gamma\)是负\(L1\)范数(表示样本的难易程度)和负\(L2,1\)范数(表示样本多样性)的参数,负\(L2,1\)范数可记为:
\[- ||\mathbf{V}||_{2,1} = - \sum_{j=1}^b ||\mathbf{v^{(j)}}||_2.\]SPLD引入一个新的自步学习正则项:负\(L2,1\)范数,倾向于从多个簇中选择具有多样性的样本。在应用统计学中,参数矩阵\(V\)的\(L2,1\)范数会导致\(V\)的群组稀疏性(group-wise sparse),例如:非零元素倾向于聚集在少量簇或者少数参数矩阵的列中。反之,负\(L2,1\)范数就会起到群组稀疏性的反作用,即非零元素倾向于分布在更多的列内。换句话说,这种反群组稀疏性可以理解为样本的多样性。
SPLD依然采用ACS (Alternative Convex Search)方法优化整个目标函数,固定一组参数\(w\)的同时,更新另一组参数\(v\),实现参数集合的交替优化。但与传统SPL不同之处在于,SPLD引入的自步学习正则项(负\(L2,1\)范数)是非凸的,而SPL中采用的\(L1\)范数是凸函数。因此,常用的梯度下降或次梯度下降算法无法直接用于优化参数矩阵\(V\)。SPLD的另一亮点则在于提出一种简单却有效的方法优化该非凸问题,同时可以保证获得参数矩阵的全局最优闭式解(global closed-form optimum):
对于各簇内\(v^{(j)}\)的样本,按照样本损失\(f(x_i, y_i, w)\)从小到大排序\(i = (1,\ldots, n_j)\),如果样本损失\(f(\cdot)\leq \lambda + \frac{\gamma}{\sqrt{i} + \sqrt{i-1}}\)时,令\(v_i^{(j)} = 1\)。随着排序\(i\)的增加,决定样本是否被选择的阈值\(\frac{\gamma}{\sqrt{i} + \sqrt{i-1}}\)越来越低,排在后面的样本即损失较大(但不会非常大)的样本仍然有可能会被自步学习选中。但是传统SPL则不具有这样的性质,SPL决定样本选择的阈值仅由\(\lambda\)决定,这就意味着当把所有样本按照损失排序后,排在前列的样本很有可能来自于SPLD中的其中一个或少数个簇中,忽略了样本的多样性;而SPLD可以实现将排在较后位置的样本纳入训练过程,这样就避免了仅从一个或少数个簇内选择样本。
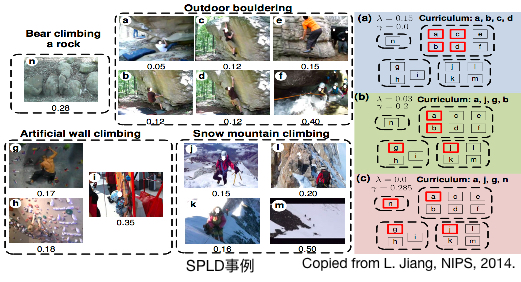
例如:上图中样本来自于TRECVID MED数据集的“Rock Climbing”事件,其中包含Bear Climbing、Outdoor Climbing、wall climbing和mountain climbing四种子类型的“Rock Climbing”事件。对于SPL而言,隶属于Outdoor climbing的样本损失较小、损失排序靠前,因此在做样本选择时,SPL倾向于选择来源于同一子类型(Outdoor climbing)的样本,而SPLD会选择部分损失排序位置靠后的样本,这些样本就可能来源于其他子类型(wall climbing和mountain climbing),实现样本选择的多样性。
3. SPLD优化
本节内容主要详细阐述SPLD中是如何优化参数\(v\),解决\(L2,1\)范数的非凸优化问题。
SPLD优化的目标函数为:
\[\min \limits_{\mathbf{v} \in [0,1]^n} E(\mathbf{w}, \mathbf{V}; \lambda, \gamma) = \sum_{i=1}^n v_i L(y_i, f(\mathbf{x_i}, \mathbf{w})) - \lambda \sum_{i=1}^n v_i - \gamma ||\mathbf{V}||_{2,1}\]其中,\(L(y_i, f(\mathbf{x_i}, \mathbf{w}))\)表示样本\(x_i\)的损失或者负似然函数值,\(l_{2,1}\)范数\(\parallel\mathbf{V}\parallel_{2,1}\)表示Group Sparsity。为后续撰写方便,我们将待优化目标函数\(E(\mathbf{w}, \mathbf{V}; \lambda, \gamma)\)和样本损失\(L(y_i, f(\mathbf{x_i}, \mathbf{w}))\)记为\(\mathrm{E}(v)\)和\(L_i\)。
因为我们认为数据是异质性的,可以被划分或聚类至\(b\)个簇中,因此,求和符号可以从\(\sum_{i=1}^n\)改写为\(\sum_{j=1}^b\sum_{i=1}^{n_j}\),即
\(E(v) = \sum_{j=1}^b E(\mathbf{v}^{(j)})\),
其中,\(E(\mathbf{v}^{(j)}) = \sum_{i=1}^{n_j}v_i^{(j)} L_i^{(j)} - \lambda \sum_{i=1}^{n_j}v_i^{(j)} -\gamma \parallel \mathbf{v}^{(j)} \parallel_2\),\(L_i^{(j)}\)表示第\(j\)个簇中第\(i\)个样本的损失值。很明显,原目标优化问题可以分解为一系列多个子优化问题:
\(\mathbf{v}^{(j)\star} = arg \min \limits_{\mathbf{v}^{(j)} \in [0,1]^{n_j}} E(\mathbf{v}^{(j)})\)。
对于任意一个子问题,因为自步学习的参数\(v\)起到选择样本的作用,其取值为0或1,我们假设向量\(\mathbf{v}^{(j)}\)不等于0的元素的个数为\(k\),即向量的秩为\(k\),可记为\(\parallel \mathbf{v}^{(j)} \parallel_0 =k\),它可作为各子优化问题的限制条件来避免选择所有样本。因此,我们定义任意一个子问题的优化可以改写为
\[\mathbf{v}^{(j)\star} = arg \min \limits_{\mathbf{v}^{(j)} \in [0,1]^{n_j} \\ \parallel \mathbf{v}^{(j)} \parallel_0 =k } E(\mathbf{v}^{(j)}) = arg \min \limits_{\mathbf{v}^{(j)}(k)} E(\mathbf{v}^{(j)}(k))\]上式代表\(\mathbf{v}^{(j)\star}\)的可行解是\(\mathbf{v}^{(j)}(1), \ldots, \mathbf{v}^{(j)}(n_j)\)中的一个,可以保证优化的子问题取得极小值。
不失一般性,首先,对于第\(j\)个子优化问题中的样本集合\((x_1^{(j)}, x_2^{(j)}, \ldots, x_{n_j}^{(j)})\)对应的损失值按从小到大升序排列,且\(\mathbf{v}^{(j)}(1), \ldots, \mathbf{v}^{(j)}(n_j)\)中\(k\)个元素值不等于0,对应地,待优化目标函数可记为:
\begin{equation}
\begin{split}
E(\mathbf{v}^{(j)}(k)) & = \sum_{i=1}^{n_j}v_i^{(j)} L_i^{(j)} - \lambda \sum_{i=1}^{n_j}v_i^{(j)} -\gamma \parallel \mathbf{v}^{(j)} \parallel_2 \
& = \sum_{i=1}^{n_j}v_i^{(j)} L_i^{(j)} - \lambda k - \gamma \sqrt{k}
\end{split}
\end{equation}
然后,对于序列\(E(\mathbf{v}^{(j)}(1)),\ldots, E(\mathbf{v}^{(j)}(n_j))\)中任意两个相邻元素计算二者的差值\(diff_k\):
\begin{equation}
\begin{split}
diff_k & = E(\mathbf{v}^{(j)}(k+1) - E(\mathbf{v}^{(j)}(k) \
& = L_{k+1}^{(j)} - \lambda - \gamma(\sqrt{k+1} - \sqrt{k}) \
& = L_{k+1}^{(j)} - (\lambda + \gamma \frac{1}{\sqrt{k+1} + \sqrt{k}})
\end{split}
\end{equation}
对于差分计算公式,\(L_{k}^{(j)}\)代表样本的损失,因为在开始我们对第\(j\)个子优化问题中所有样本的损失做了升序排列,因此随着\(k\)的增加\((k=1,\ldots,n_j)\),\(L_{k}^{(j)}\)是单调递增的序列,而对应的\((\lambda + \gamma \frac{1}{\sqrt{k+1} + \sqrt{k}})\)是单调递减序列,进而我们可以发现差分序列\(diff_k\)是单调递增序列。
最后,对于差分序列,当\(diff_k < 0\)时,待优化的目标函数\(E(\mathbf{v}^{(j)}(k))\)呈递减趋势,当\(diff_k > 0\)时,目标函数\(E(\mathbf{v}^{(j)}(k))\)呈递增趋势。显然,当\(diff_k = 0\)时,目标函数取得极小值。因此,目标函数对应\(\mathbf{v}^{(j)\star}\)的解为
\begin{equation}
\begin{split}
& diff_k = 0 \
& \Leftrightarrow L_{k+1}^{(j)} = \lambda + \gamma \frac{1}{\sqrt{k+1} + \sqrt{k}} \
& \Leftrightarrow L_{k}^{(j)} = \lambda + \gamma \frac{1}{\sqrt{k} + \sqrt{k-1}}
\end{split}
\end{equation}
综上所述,我们可以证明,对于各簇内的样本,按照样本损失\(L_{i}^{(j)}\)从小到大排序\(i = (1,\ldots, n_j)\),如果样本损失\(L_{i}^{(j)}(\cdot)\leq \lambda + \frac{\gamma}{\sqrt{i} + \sqrt{i-1}}\)时,令\(v_i^{(j)} = 1\),否则令\(v_i^{(j)} = 0\)。