1. 随机变量的定义
说到随机变量生成,首先要谈的是什么是随机变量?
随机变量是指:给定样本空间(S,F),如果存在样本空间上的实值函数\(X: S \rightarrow R\subset F\),则X称为随机变量。从定义可以发现,随机变量实质上是函数,并不是变量。相对随机变量而言,变量则是使用字母表示已知或者未知数字的概念,亦或在计算机学科中泛指命名空间。
Wiki百科上给出了随机变量的很浅显的例子,如果事件空间为随机掷两个骰子,则整个事件空间由6*6=36个元素组成,那么随机变量可以是多种形式,比如:随机变量X(获得的两个骰子的点数和)或者随机变量Y(获得的两个骰子的点数差)。当然,根据随机变量的取值有限或者无限可将随机变量分为离散随机变量和连续随机变量。
2. 分布函数
在涉及到R中随机变量产生的问题之前,首先普及几个概率论的基本概念:概率质量函数、概率密度函数和累积分布函数。
概率质量函数为probability mass function,简写为pmf,是随机变量在各特定取值上的概率。概率质量函数的所有取值必为非负,且总和为1。概率质量函数和概率密度函数不同之处在于:概率质量函数是对离散随机变量定义的,本身代表该值的概率;概率密度函数是对连续随机变量定义的,本身不是概率,只有对连续随机变量的概率密度函数在某区间内进行积分后才是概率。常见的概率质量函数有二项分布、伯努利分布和泊松分布等。
概率密度函数为Probability Density Function,以小写pdf标记。概率密度函数是针对连续型随机变量而言的,它是描述随机变量在某个确定的取值点附近的可能性的函数。其值并不是指随机变量取某个值的概率。随机变量的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分,即随机变量X的取值只取决于累积分布函数。最常见的概率密度函数为正态分布的概率密度函数:
\[f(x) = \frac{1}{\sigma\sqrt{2\pi}}\exp{\frac{-(x-\mu)^2}{2\sigma^2}}\]那么问题来了:pdf不代表随机变量取值的概率,那么它存在的意义是什么呢?在贾俊平老师《统计学》一书中指出:概率密度函数的函数值大小不能表示真正意义上取值的概率,连续型随机变量在给定区间内取值的概率对应的是概率密度函数在该区间上围成的面积,这印证了连续型随机变量在任意一点的概率值为0,所以连续型随机变量在区间上取值的概率与这个区间是开区间还是闭区间无关。概率密度函数的取值只能表示随机变量取值在该点附近的概率大小,一般pdf取值越大则随机变量取值在该点附近的概率越大。综上所述,随机变量取值在该点附近的概率和随机变量取值在该点的概率还是不一样的,这也说明了概率密度函数和概率质量函数的区别。
累积分布函数Cumulative Distribution Function,常记为CDF(这里很多人会将累积分布函数称为概率分布函数,这是错误的。wiki百科上明确指出概率分布函数是概率密度函数,这种称法很可能会和累积分布函数混淆)。累积分布函数是概率密度函数的积分,因为如果从最简单的离散情况讲起,累积分布函数其实就是每一点的概率累加。将“求和”这一概念推广到连续情况,就是求积分,当随机变量取值趋近于正无穷时,累积分布函数值为1。需要声明的一点是:这里我也不太确定是先有cdf还是先有pdf,这部分分析的还不够透彻。
3. 随机变量生成
好了,讲完概率分布的理论后,我们开始逐渐进入R中随机变量生成的问题。
对于每一个随机变量,每个随机变量的缩写再在其前加上字母d代表概率密度函数或概率质量函数,字母p代表累积分布函数,q代表分位函数,r代表该随机变量序列的生成。例如:对于二项分布而言,dbinom、pbinom、qbinom和rbinom对应二项分布的概率密度函数、概率累计函数、分位函数和随机生成的二项分布的序列。
R中所有随机变量的产生都需要通过均匀伪随机数产生器(uniform random number generator)生成。0-1之间的均匀伪随机数可以使用runif(n)函数实现,生成a到b之间的均匀随机数则可通过runif(n, a, b)。通过均匀分布随机数生成任意概率分布随机数的方法称为逆变换法(Inverse Transform method)。
假设随机变量U服从[0, 1]上的均匀分布,X为累积分布函数为\(F_X(x)\)的随机变量,则\(U = F_X(X)\sim Uniform(0,1)\)。定义\(F_X(x)\)的逆变换为\(F_X^{-1}=inf\{x:F_X(x)=\mu\}, 0<\mu<1\)。
对于所有随机变量的取值x而言:
\[P(F_X^{-1}(U) \le x)=P(inf\{t:F_X(t)=U\}\le x)=P(U\le F_X(x))=F_U(F_X(x))=F_X(x))\]根据上面的推导,如果得到一个服从[0, 1]上的均匀分布的随机序列\(\mu\),那么\(F_X^{-1}(\mu)\)服从和随机变量X具有同样的分布。综上所述,如果想要生成一个随机变量X,首先生成一个服从均匀分布的随机变量,然后计算其随机变量累积分布函数的逆变换\(F_X^{-1}(\mu)\)即可。
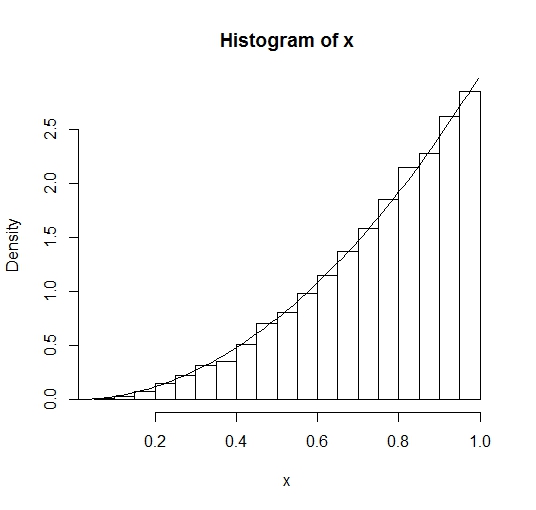
下面结合R说明R是如何生成一个概率密度函数为\(3x^2\)的随机变量,其中\(0<x<1\)。因为\(pdf=3x^2\),则\(cdf=x^3\),其累积分布函数的逆变换为\(x^\frac{1}{3}\)。按照逆变换的两步法将服从均匀分布的随机变量序列带入cdf的逆变换即可获得想要获得的随机变量序列。下面为示例代码:
#采用逆变换法生成概率密度函数为3*x^2的随机变量
n <- 10000
u <- runif(n)
x <- u^(1/3)
hist(x, prob=T) #直方图
y<- seq(0, 1, 0.01)
lines(y, 3*y^2)
生成随机变量序列的直方图如下: