1. 梯度下降算法
在机器学习篇章的开始机器学习-梯度下降算法,我对梯度下降算法的推导证明以及应用都做了详细介绍,这里就不在做过多推导,直接给出梯度下降的计算公式:
\[x^{(k)}=x^{(k-1)}-t_k \nabla f(x^{(k-1)}), \, k=1,2,3,\ldots\]对于梯度下降,其基本释义为如果对函数在点\(x\)做泰勒二阶展开,会得到如下公式:
\[f(y) \approx f(x) + \nabla f(x)^T(y-x)+\frac{1}{2} \nabla^2 f(x)^T \parallel y-x \parallel_2^2\]如果我们采用\(\frac{1}{t}I\)代替\(\nabla^2 f(x)\),那么函数就会变成关于\(y\)的二次函数,为:
\[f(y) = f(x) + \nabla f(x)^T(y-x)+\frac{1}{2t} \parallel y-x \parallel_2^2\]该函数明显是以\(y\)为自变量通过点\((x,f(x))\)的二次函数,该函数用于逼近在点\(x\)附近的目标函数。总体而言,泰勒公式是是用多项式函数去逼近光滑函数,利用函数在某点的信息描述其附近取值的公式。如果函数足够光滑的话,在已知函数在某一点的各阶导数值的情况之下,泰勒公式可以用这些导数值做系数构建一个多项式来近似函数在这一点邻域中的值。因此,接下来我们需要做的是寻找在该次迭代下这个二次多项式函数取得极小值的点。(题外话,如果不选择此步骤的替换,下降算法就会变成牛顿算法)。
我们对关于\(f(y)\)的二次多项式函数求梯度,获得该函数可以取得极小值的点,然后把该点作为下一次迭代的点,函数\(f(y)\)的导数为:
\[\nabla f(y)=\nabla f(x)+\frac{1}{t}(y-x)\]接下来,我们令导数等于0,可以获得:
\[y=x-t\nabla f(x)\]所以,我们就找到了下一次迭代的参数的解。很明显的是,如果t很小,那么\(y\)更趋近于\(x\);如果\(t\)很大,就是使得每次下降的步长很大。Ryan教授也给出了梯度下降算法的迭代示意图,如下:
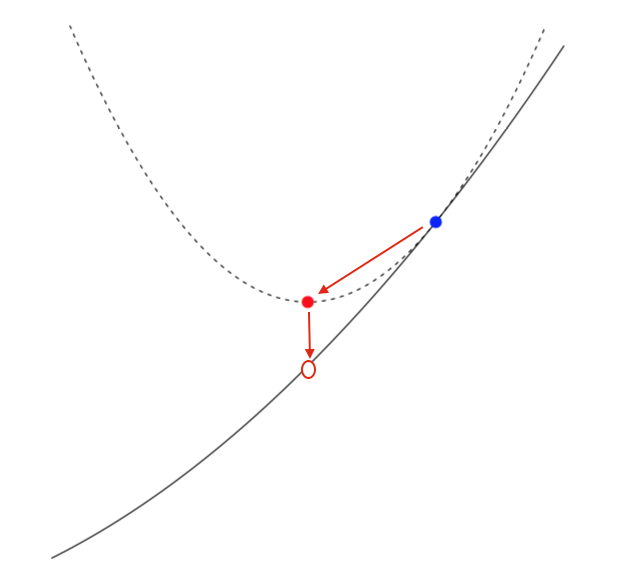
我想,看完这个图,大多数人应该会明白梯度下降中所谓的下降的含义了~
对于梯度下降算法的每一次迭代,参数的更新都会从蓝点移动到红点,直至逼近原目标函数的极值。同样可以看出,\(t\)越小,\(\frac{1}{t}\)越大,二次函数越窄,因此,步长越小。下图是固定步长后,梯度下降迭代结果:
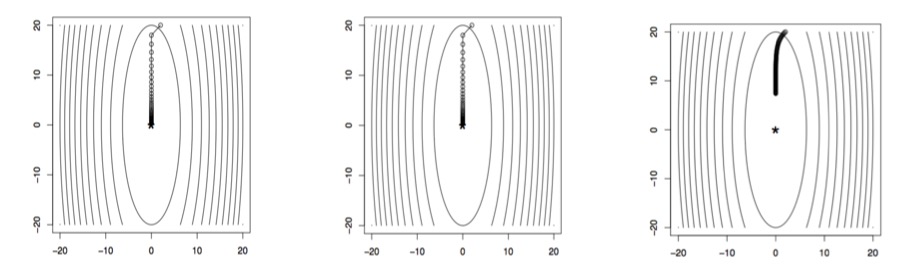
左图表明,当\(t\)较大,迭代次数为8时,迭代结果会发散,不会收敛;中图表明,当\(t\)较大适中时,迭代40次,即可非常逼近最优解;当右图表明,当\(t\)较小,迭代次数为100时,迭代结果仍不能逼近最优解,速度太慢。
2. 梯度下降步长选择方法
对于梯度下降算法而言,当步长设为固定值的时候,可能会造成收敛过慢,或者不收敛的情况,因此,我们需要梯度下降算法在迭代过程中自动更新步长,防止上述情况的发生。一般解决该问题的方法有两种:Exact line search和Backtracking line search。由于,实际应用中Exact line search方法效果较差,这里就主要介绍Backtracking line search方法。
该方法基本步骤为:
- 设置参数\(0 < \beta < 1\)和\(0 < \alpha \leq 1/2\);
- 对于每次迭代,设\(t=1\),如果\(f(x-t \nabla f(x)) > f(x) - \alpha t \parallel \nabla f(x) \parallel_2^2\),令\(t=\beta t\)直至不满足上述条件,然后令\(x^+ = x-t \nabla f(x)\)。
- 达到梯度下降停止迭代条件,停止迭代。
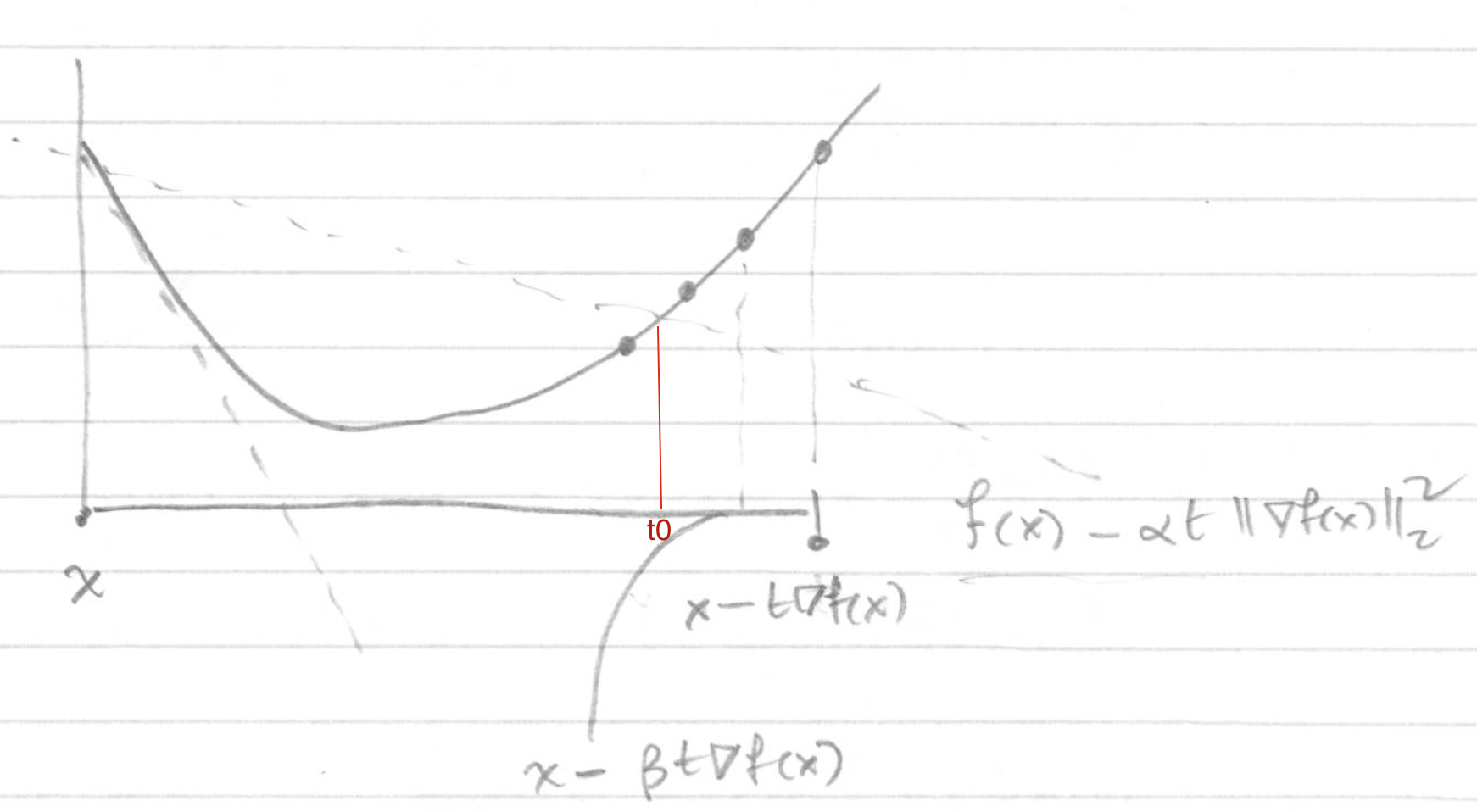
该方法成为后退法是因为先从\(t=1\)开始,步进单位步长,如果步长过长,则压缩步长,直至满足停止压缩的条件。如下图:
当\(t=1\)时,步长为\(-\nabla f(x)=\vartriangle x\),通过梯度下降,会更新到红色的点。但是此时,\(f(x+t \vartriangle x) > f(x) - \alpha t \parallel \nabla x \parallel^2\),根据Backtracking line search理论需要压缩步长。因此,令\(t'=\beta t\),这时步长和判断阈值都会变小,继续与阈值比较,直至\(t‘\)满足\(f(x+t' \vartriangle x) < f(x) - \alpha t' \parallel \nabla x \parallel^2\)时,停止对\(t\)的压缩,完成一次迭代过程,通过梯度下降更新到绿色的点。
该方法思想就是当梯度下降趋近于最优解的时候,减小\(t\)的值,让每次步长变小,这样可以不会发生发散或者在最优解附近波动的情况,实现步长的自适应。但是从图上看出会不会一直不会出现满足停止压缩的条件呢?即会不会出现\(f(x+t' \vartriangle x) < f(x) - \alpha t' \parallel \vartriangle x \parallel^2\)的情况呢?接下来就证明这个问题:
证明:
当\(t\)被压缩至很小的时候,展开\(f(x+t\vartriangle x)\)获得\(f(x+t\vartriangle x) \approxeq f(x) + t \nabla f(x)^T \vartriangle x < f(x)+\alpha t \nabla f(x)^T \vartriangle x\),因为\(\vartriangle x = - \nabla f(x)\),所以,\(\alpha t \nabla f(x)^T \vartriangle x\)绝对值更小,使得不等式右边更大,既证上述结论。
Boyd凸优化一书中也给出了一个比较形象的图来解释Backtracking line search该问题,如下图,\(t_0\)对应\(t\)需要被压缩到的最大值,即上面一条虚线经过函数的点;如果不对\(t\)进行压缩,则为下面的虚线对应的步长。因此,\(t \in (\beta t_0, t_0])\):
Backtracking line search方法存在两个参数\(\alpha\)和\(\beta\),分别控制判断阈值大小和压缩比例,该参数属于经验参数,一般情况会将\(\alpha\)设定为\([0.01,0.3]\),意味着我们根据线性扩展(Linear Extrapolation involves using a linear equation to predict values that go beyond your data set)接受函数\(f\)1%~30%的变化幅度(减小);参数\(\beta\)一般选择为\([0.1,0.8]\)范围内,\(\beta\)越大,步长压缩幅度越小,意味着在一次迭代过程中会压缩多次,而\(\beta\)越小,步长压缩幅度很大,可能会一次满足\(t \in (0, t_0])\)的条件,但会使得算法总体下降速度过慢,意味着后退搜索过于粗糙。
但是,为什么Backtracking line search方法会设定为\(f(x) - \alpha t \parallel \nabla f(x) \parallel_2^2\)形式呢?在后面对于梯度下降算法的收敛性的证明中可能会给出一些端倪~
3. 梯度下降算法收敛性
定理:假设\(f\)为凸函数且处处可微,那么梯度下降算法在固定步长\(t\)的情况下会满足下式:
\[f(x^{(k)}) - f^{\ast} \leq \frac{\parallel x^{(0)}-x^{\ast} \parallel_2^2}{2tk}\]我们就称梯度下降算法收敛速度为\(O(1/k)\),其中\(k\)为迭代次数。
证明:
因为\(\nabla f\)是Lipschitz continuous,即对于任意\(x,y\),\(\parallel \nabla f(x)-\nabla f(y)\parallel_2 \leq L \parallel x-y \parallel_2\),所以对于任意\(x,y\),Lipschitz continuous等价于\(f(y)\)满足以下等式:
\[f(y) \leq f(x) + \nabla f(x)^T(y-x)+\frac{L}{2}\parallel y-x \parallel_2^2\]然后,我们令\(y=x^+=x-t\nabla f(x)\),带入上式得到:
\begin{split}
f(x^+) & \leq f(x) + \nabla f(x)^T(x-t\nabla f(x)-x) + \frac{L}{2}\parallel x-t\nabla f(x)-x \parallel_2^2 \
& = f(x) - (1-\frac{Lt}{2})t \parallel \nabla f(x) \parallel_2^2
\end{split}
取\(t=1/L\),上式可变为\(f(x^+) \leq f(x)-\frac{t}{2} \parallel \nabla f(x) \parallel_2^2\)。
同时,如果\(x^{\ast}\)为函数最优解,根据First-order characterization,对于\(\forall x\),则\(f^{\ast}=f(x^{\ast}) \geq f(x) + \nabla f(x)^T (x^{\ast} - x)\)。
故,\(f(x) \leq f(x^{\ast}) + \nabla f(x)^T (x - x^{\ast})\)
又将上式带入\(f(x^+) \leq f(x)-\frac{t}{2} \parallel \nabla f(x) \parallel_2^2\)中,获得函数\(f(x^+)\)的上界:
\begin{split}
f(x^+) & \leq f(x^{\ast}) + \nabla f(x)^T (x - x^{\ast}) -\frac{t}{2} \parallel \nabla f(x) \parallel_2^2 \
& = f(x^{\ast}) + \frac{1}{2t} (\parallel x-x^{\ast}\parallel_2^2 - \parallel x^+ - x^{\ast} \parallel_2^2)
\end{split}
接着我们来证明为什么会出现上面的等式,因为:
\begin{split}
\parallel x^+ - x^{\ast} \parallel_2^2 & = \parallel x-t\nabla f(x) - x^{\ast} \parallel_2^2 \
& = \parallel x - x^{\ast} \parallel_2^2 - 2t \nabla f(x)^T (x-x^{\ast}) + t^2 \parallel \nabla f(x) \parallel_2^2
\end{split}
所以,将上面结果带入至\(f(x^{\ast}) + \frac{1}{2t} (\parallel x-x^{\ast}\parallel_2^2 - \parallel x^+ - x^{\ast} \parallel_2^2)\)可发现等式成立。
综上所述,我们获得一个重要的不等式,其中\(x\)表示当次迭代的值,\(x^+\)表示下次迭代的值,即:
\[f(x^+) - f(x^{\ast}) \leq \frac{1}{2t} (\parallel x-x^{\ast}\parallel_2^2 - \parallel x^+ - x^{\ast} \parallel_2^2)\]上式表明,对于每一次迭代,\(i=1,2,\ldots,k\)均满足上式:
\[f(x^{i}) - f(x^{\ast}) \leq \frac{1}{2t} (\parallel x^{i-1}-x^{\ast}\parallel_2^2 - \parallel x^i - x^{\ast} \parallel_2^2)\]对所有\(k\)次迭代求得上式的和,为:
\[\sum_{i=1}^k (f(x^{i}) - f(x^{\ast})) \leq \frac{1}{2t} \parallel x^0-x^{\ast}\parallel_2^2\]最后,根据梯度下降的原理,对于第\(i\)次迭代和第\(i+1\)次迭代,也服从单调递减的性质,所以:
\[f(x^{k}) - f(x^{\ast}) \leq \frac{1}{k} \sum_{i=1}^k (f(x^{i}) - f(x^{\ast}))\]故,证明出\(f(x^{k}) - f(x^{\ast}) \leq \frac{1}{2tk} \parallel x^0-x^{\ast}\parallel_2^2 = C/k\),如果通过梯度下降算法想要获得\(\epsilon\)-optimal的解,即\(f(x^{k}) - f(x^{\ast}) \leq \epsilon\),我们至少需要\(O(1/ \epsilon)\)次迭代,因此,梯度下降算法的收敛速度为\(O(k)\)。
上述证明看似很无聊,实际上对于机器学习相关研究具有重要作用,试想我们想要求解的目标函数往往很复杂,会包含许多约束,而上式是证明无约束凸优化问题下的收敛性,如果我们对上述目标函数做变换,无论在写论文还是科研中都需要去证明自己选用的下降算法会收敛到函数的局部最优解,因此,我们可以利用上述相似的方法证明自己算法的收敛性,而不必盲目的使用梯度下降算法求解,这样从理论上是行不通的。我们在学习别人论文的时候同样会见到许多学者在文章中会选用大部分篇幅来证明自己优化结果的可靠性,这就凸显出上面证明过程的实用性。
4. Pros and Cons
-
Pro: simple idea, and each iteration is cheap;
-
Pro: very fast for well-conditioned, strongly convex problems;
-
Con: often slow, because interesting problems aren’t strongly convex or well-conditioned;
-
Con: can’t handle nondifferentiable functions.