1. 定义
置换检验(Permutation Tests)也称为随机试验,属于统计显著性检验的一种,基于假设检验,以原假设为条件,假定二组没有差别,由此将二组样本合并,从中以无放回方式进行抽样,分别归入两个组再计算统计量,反复进行由此得到置换分布(构造新的经验分布),在此基础上进行显著性检验推断是否拒绝原假设。例如:如果要判断两个样本集是否来源于同一分布,那么原假设就是二者来自于同一分布,所以如果将两个样本集进行顺序上的置换,多次重新做无放回抽样后,对分布的参数统计量的估计与置换前的统计量估计应保持大致相同(“大致”的程度则通过P值来说明)。置换检验是一种不同于Bootstrap的重采样方法,不同之处在于置换检验再抽样过程中是无放回抽样。
>置换检验的场景是,一次试验中,我们为试验单元随机分配不同的处理(treatment),假设这里只有两种处理水平A和B,我们想知道两种处理在试验单元的某项指标上是否有显著差异。逻辑是这样:假设处理毫无效果,那么某一个试验对象的指标将不受处理影响,不管我们给老鼠嗑的是A药还是B药,结果都一样,那么我们可以把处理的标签随机打乱(某些A、B随机互换),打乱后A组和B组的差异**不应该**会和原来的**差异很不一样**(因为药不管用嘛),否则,我们恐怕得说,药还是管用的。就这样,我们随机打乱标签很多次,形成一个“人工生成”的AB差异分布(因为我们生成了很多个差异值),看原来的差异在这个分布的什么位置上,如果在很靠近尾巴的位置上,那么就认为P值很小。
2. 置换分布
对置换检验熟悉的人是否有想过,好像我们一直没谈到什么分布的假设,那这个概率值(P值)是从哪里生出来的?
这时候就涉及到置换分布(Permutation Distribution)了。假设两个随机变量\(X\)和\(Y\),其抽样样本\(X_1,\ldots,X_n\)和\(Y_1,\ldots,Y_m\)分别来自于服从\(F_X\)和\(F_Y\)的分布,我们定义\(Z\)是\(X\)和\(Y\)抽样样本的组合(\(Z=X\cup Y\)),记为\(\nu=\{Z_1,\ldots,Z_n,Z_{n+1},\ldots,Z_{n+m}\}=\{Z_1,\ldots,Z_N\}\)。其中,当\(1 \le i\le n\)时,\(Z_i=X_i\);当\(n+1 \le i \le n+m\)时,\(Z_i=Y_{i-n}\)。
对于随机变量\(Z\)而言,置换检验是对\(\nu\)进行多次随机无放回抽样,每次在N个样本中抽取n个作为随机变量\(X\)其余作为随机变量\(Y\),一共可能有\(({N \atop n})\)种可能组合方式,这些组合方式记为\(\pi_j(\nu)\),其中\(j=1,\ldots,({N \atop n})\)。如果要检验X和Y在某个统计量\(\theta\)上是否有显著性差异,那么对于统计量\(\theta\)而言,\(\hat{\theta}(X,Y)=\hat{\theta}(\nu,\pi(\nu))\)。所以对于不同的\(\pi_j(\nu)\),可以获得\(\theta\)的不同显著性检验结果,我们可以记\(\{\hat{\theta}^*\}=\{\hat{\theta}(Z,\pi_j(\nu)),j=1,\ldots,({N \atop n})\}\),并将之称为\(\hat{\theta}^*\)的置换分布。同时,我们可以获得\(\hat{\theta}^*\)的累积分布函数cdf为:
\(F_{\theta^*}(t)=P(\theta^* \le t)=({N \atop n})^{-1} \sum_{j=1}^NI(\hat{\theta}^{(j)} \le t)\)。
有了置换分布\(\hat{\theta}^*\)以及置换分布的累积分布函数,我们就可以计算\(\hat{\theta}\)的P-value。如果通过X和Y计算的\(\hat{\theta}\)相对于置换分布\(\hat{\theta}^*\)中的\(\theta\)值较大,则\(\hat{\theta}\)为显著的,应拒绝原假设。\(\hat{\theta}\)达到的显著水平(achieved significance level-ASL)P-value可定义为:
\(P(\hat{\theta}^* \ge \hat{\theta})=({N \atop n})^{-1} \sum_{j=1}^NI(\hat{\theta}^{(j)} \ge \hat{\theta})\)。
3. 一般步骤
综上所述,置换检验的一般步骤为:
- 计算两个观察样本的检验统计量\(\hat{\theta}(X,Y)=\hat{\theta}(Z,\pi_j(\nu))\);
- 重复置换抽样\(b=1,\ldots,B\):
- 生成两个新的样本集合\(\pi_b=\pi(\nu)\);
- 估计新样本集合的检验统计量\(\hat{\theta}^{(b)}=\hat{\theta}^*(Z,\pi_b)\);
- 计算P值\(\hat{p}=\frac{1+\sum_{b=1}^BI(\hat{\theta}^{(b)} \ge \hat{\theta})}{B+1}\);
- 判断在显著水平\(\alpha\)下是否拒绝原假设\(\hat{p} \le \alpha\)。
4. 实例
下面通过一个例子来说明Permutation Tests的计算过程,另两个个实例可戳Permutation Test置换检验和R Studio上Hypertension Dataset实例
假设我们想知道大豆(soybean)与亚麻籽(linseed)两种种子重量是否一致,如果二者都服从同方差的正态分布,我们可以通过双样本T检验来检测二者重量的均值是否有差异来证明。但是,我们不清楚这两个随机变量服从那种分布,所以需要采用非参数估计的假设检验方法来证明二者重量是否一致,即采用置换检验。通过执行下面的代码我们可以发现随机变量X(大豆)和随机变量Y(亚麻籽)的样本量分别为14和12,但如果采用置换检验其组合方式一共有9,657,700种可能。所以即使对于小样本量而言,置换检验的计算代价仍然很高,我们这里则需要随机抽样B次(其中\(26 \ll B \ll 9,657,700\))来近似估计统计量。
\[({n+m \atop n})=({26 \atop 14})=\frac{26!}{14!12!}=9,657,700\]#读取数据 attach(chickwts) x <- sort(as.vector(weight[feed == "soybean"])) y <- sort(as.vector(weight[feed == "linseed"])) detach(chickwts) print(x) print(y)

接下来我们采用置换检验来判断大豆与亚麻籽两种种子重量是否一致,R代码如下:
#对x和y进行t检验
t0 <- t.test(x,y)$p.value
#置换检验
R <- 888
z <- c(x,y)
K <- 1:(length(x) + length(y))
reps <- numeric(R)
for (i in 1:R){
#产生抽样样本
k <- sample(K, size=length(x), replace=FALSE)
x1 <- z[k]
y1 <- z[-k]
#t检验
reps[i] <- t.test(x1, y1)
}
#计算p-value
p <- mean(c(t0, reps) >= t0)
sprintf("随机变量X和Y的T检验结果为%g,置换检验的P-value为%g", t0, p)
hist(unlist(reps), main="置换检验", freq=FALSE, xlab="T (p)",
breaks = "scott")
points(t0, 0, cex=1, pch=16)

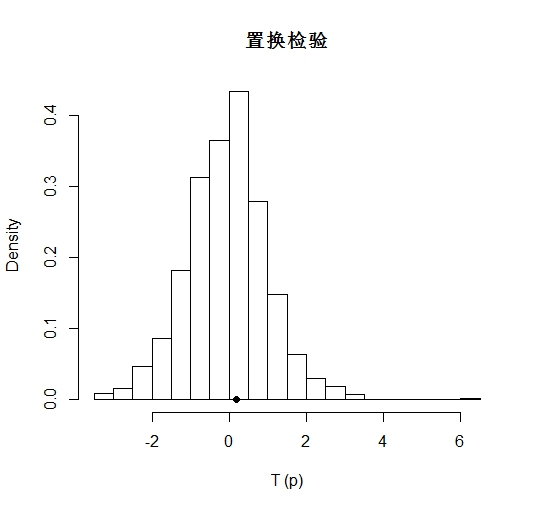
程序中的p-value是置换分布中\(\hat{p}\)大于t0(观察变量的T检验P值)的比例,对于双尾T检验,如果\(\hat{p} \le 0.5\),ASL为\(2\hat{p}\);如果\(\hat{p} \ge 0.5\),ASL为\(2(1-\hat{p})\)。这里显著水平ASL为0.41 > 0.1,t0值较小,不能拒绝原假设。